请注意,本文编写于 407 天前,最后修改于 337 天前,其中某些信息可能已经过时。
目录
1. 前言:
Mac安装tesseract和python使用pytesseract、pillow包提取图片中中文以便断言(该方法为断言的通法,但是会增加断言的时间,本人因为安卓app自动化测试过程中无法获取toast断言进而使用此法)
2. Python OCR工具pytesseract详解
pytesseract是基于python的OCR工具,底层使用的是Tesseract—OCR引擎,支持识别图片中的文字,支持jpeg,png,gif,bmp,tiff等图片格式。

OCR(Optical character recognition,光学字符识别)是一种将图像中的手写字或者印刷文本转为机器编码文本的技术。OCR技术可以将图片,纸质文档中的文本转换为数字形式的文本以便程序处理。OCR过程一般包括以下步骤:
- 1.图像预处理
- 2.文本定位
- 3.字符分割
- 4.字符识别
- 5.后处理
3. MAC环境配置
环境要求:
- Python 3.6+(本机python版本3.11.1)
- PIL库(PIL库是一个拥有图像处理能力的python第三方库,需要通过pip工具安装,安装库的名字为pillow)
- 安装Tesseract OCR
- 系统:windows/mac/linux
1. 安装Tesseract
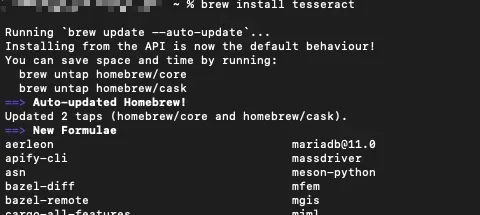
2. 查看tesseract版本
成功安装后查看tesseract版本

3. 下载中文包
- tesseract默认不支持中文,需要单独下载中文包
- 中文包下载地址:https://tesseract-ocr.github.io/tessdoc/Data-Files#data-files-for-version-400-november-29-2016

4. 中文包存放目录
cd /usr/local/Cellar/tesseract/{tesseract版本}/share/tessdata
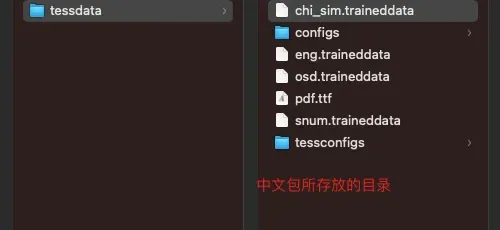
查看全部语言库:

5. python安装pytesseract和pillow

6. 识别图片文字
 代码如下:
代码如下:
python"""
@File:demo.py
Author:Qi.Zhang
@Software:PyCharm
"""
from appium import webdriver
from appium.webdriver.common.mobileby import MobileBy
from selenium.webdriver.support import expected_conditions as ec
import pytesseract # 有关该光学字符识别引擎的安装与使用请参考https://blog.csdn.net/zhengzaifeidelushang/article/details/126639801
from PIL import Image
from selenium.webdriver.support.wait import WebDriverWait
# from Config.config import desired_caps
from time import sleep
desired_caps = {
"platformName": "Android",
"platformVersion": "10",
"deviceName": "49930131",
"appPackage": "com.zkteco.entrance",
"appActivity": ".app.ui.splash.SplashActivity",
"noReset": True,
"automationName": "UiAutomator2",
"autoAcceptAlerts": True
}
driver = webdriver.Remote("http://127.0.0.1:4723/wd/hub", desired_capabilities=desired_caps)
driver.implicitly_wait(10)
login_but = driver.find_element(MobileBy.ID, 'com.zkteco.entrance:id/text_login')
login_but.click()
sleep(2)
driver.save_screenshot(r"./pictures/test.png")
im = Image.open('./pictures/test.png')
# 识别文字,并指定语言
string = pytesseract.image_to_string(im, lang='chi_sim')
print(string)
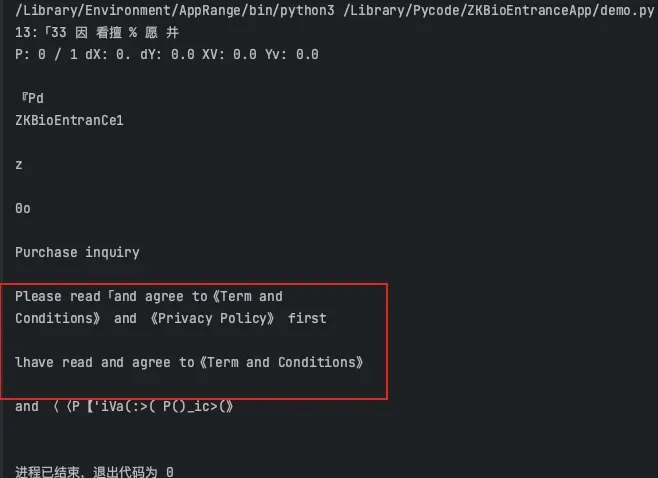
assert "Please " in string
driver.quit()
运行结果:
本文作者:精卫
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录