请注意,本文编写于 405 天前,最后修改于 337 天前,其中某些信息可能已经过时。
目录
前言:
本次采用的OCR(光学字符识别)工具为Tesseract OCR,在MAC电脑实现,目前为止,识别的效率不高,测试网站https://www.qb5.ch ,本想在实际项目中应用,但因效果太差只能拜托开发设置万能验证码😂。
1. 安装工具
- MAC系统安装tesseract:brew install tesseract.
- 验证安装:打开命令行,运行 tesseract --version 以确保 Tesseract 安装正确。
2. 编写Python脚本解析验证码
- 安装 Python 和相关依赖:
- 安装 Python(如果未安装)。
- 安装 PIL 和 pytesseract,以下是本次测试所安装的依赖,进入项目的根目录,使用命令pip install -r requirements.txt 安装依赖,安装后使用命令pip list进行验证
requirements.txtpackaging==24.1 pillow==10.3.0 pytesseract==0.3.10
- 创建一个解析验证码的 Python 脚本 parse_captcha.py,内容如下:
python"""
@File:parse_captcha.py
@time:2024/6/24 10:13
Author:Qi.Zhang
@Software:PyCharm
"""
import sys
from PIL import Image
import pytesseract
# 设置 Tesseract OCR 的路径
pytesseract.pytesseract.tesseract_cmd = '/usr/local/bin/tesseract'
def preprocess_image(image_path):
try:
# 尝试打开并加载图片
image = Image.open(image_path)
# print("Image opened successfully")
# 转换为灰度图像
image = image.convert('L')
# 应用自适应阈值二值化
image = image.point(lambda x: 0 if x < 140 else 255)
# 保存处理后的图像以供调试,保存在当前脚本目录下
output_path = "/Library/PyLearning/Range/OCR/processed_captcha.png"
image.save(output_path)
# print(f"Processed image saved as {output_path}")
return image
except IOError as e:
print(f"Error: Unable to open image file {image_path}")
print(f"IOError: {str(e)}")
return None
def recognize_captcha(image):
try:
# 使用 Tesseract 进行 OCR 识别,提取图片中的文本
captcha_text = pytesseract.image_to_string(image,
config='--psm 10 --oem 3 -c tessedit_char_whitelist=0123456789 -l '
'eng')
# print("OCR processed successfully")
return captcha_text.strip()
except pytesseract.TesseractError as e:
print(f"Error: Tesseract OCR processing failed: {str(e)}")
return None
def main():
# 检查命令行参数是否正确传入
if len(sys.argv) < 2:
print("Usage: python parse_captcha.py <image_path>")
sys.exit(1)
# 从命令行参数获取图片路径
image_path = sys.argv[1]
# print(f"Image path: {image_path}")
# 预处理图像
processed_image = preprocess_image(image_path)
if processed_image is None:
sys.exit(1)
# 识别验证码
captcha_text = recognize_captcha(processed_image)
if captcha_text:
print(captcha_text)
if __name__ == "__main__":
main()
3. 配置JMeter脚本
- 添加 Thread Group:
- 在 JMeter 中,添加一个 Thread Group。
- 添加 HTTP 请求取验证码图片:
- 在 Thread Group 下添加一个 HTTP Request 采样器,用于获取验证码图片。
- 配置该请求的路径和方法以获取验证码图片。
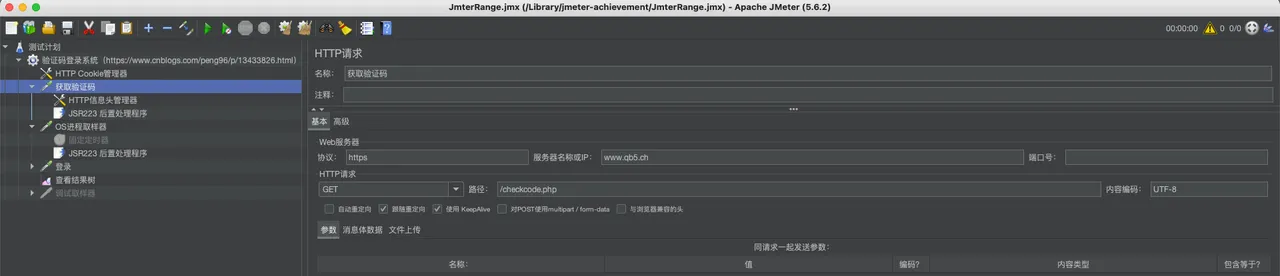
 3. 保存验证码图片:
3. 保存验证码图片:
- 在获取验证码图片的 HTTP Request 采样器下,添加一个 JSR223 PostProcessor。
- 使用以下 Groovy 脚本将响应的验证码图片保存到文件系统中:
Groovyimport org.apache.commons.io.FileUtils; // 导入 FileUtils 工具类,用于文件操作 import java.io.File; // 导入 File 类,用于表示文件对象 // 获取 HTTP 请求的响应数据(即验证码图片的字节数据) byte[] image = prev.getResponseData(); // 定义要保存验证码图片的文件路径 File file = new File("/Library/PyLearning/Range/OCR/captcha.png"); // 将字节数据写入到指定文件中 FileUtils.writeByteArrayToFile(file, image);
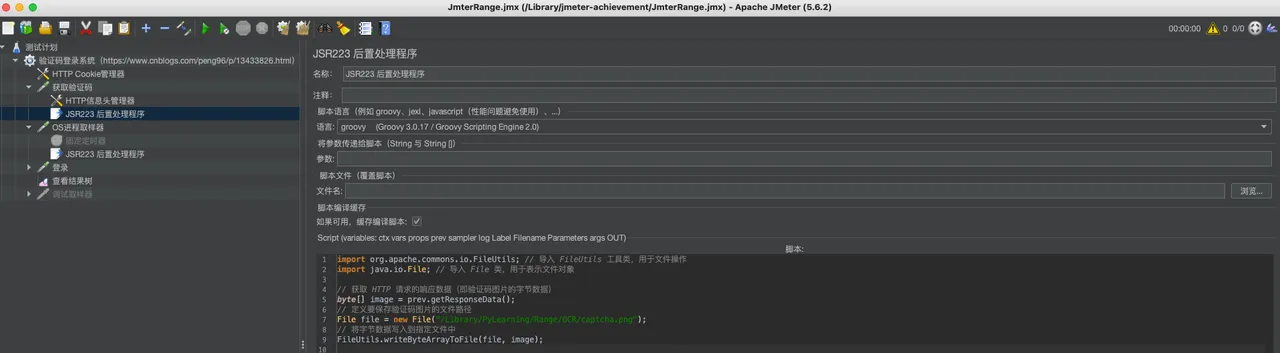 4. 调用外部 Python 脚本解析验证码:
4. 调用外部 Python 脚本解析验证码:
在 Thread Group 下,添加一个 OS Process Sampler。
配置 OS Process Sampler 如下:
- Command:python
- Command parameters:/Library/PyLearning/Range/OCR/parse_captcha.py /Library/PyLearning/Range/OCR/captcha.png
- Working directory:脚本和图片所在的目录
 5. 保存解析到的验证码文本:
5. 保存解析到的验证码文本:
- 在 OS Process Sampler 下,添加一个 JSR223 PostProcessor。
- 使用以下 Groovy 脚本将解析到的验证码文本保存为 JMeter 变量:
Groovy// 获取外部脚本执行后的输出结果(即解析到的验证码文本) String captchaText = prev.getResponseDataAsString().trim(); // 将解析到的验证码文本保存为 JMeter 变量,以便后续请求使用 vars.put("captchaText", captchaText);
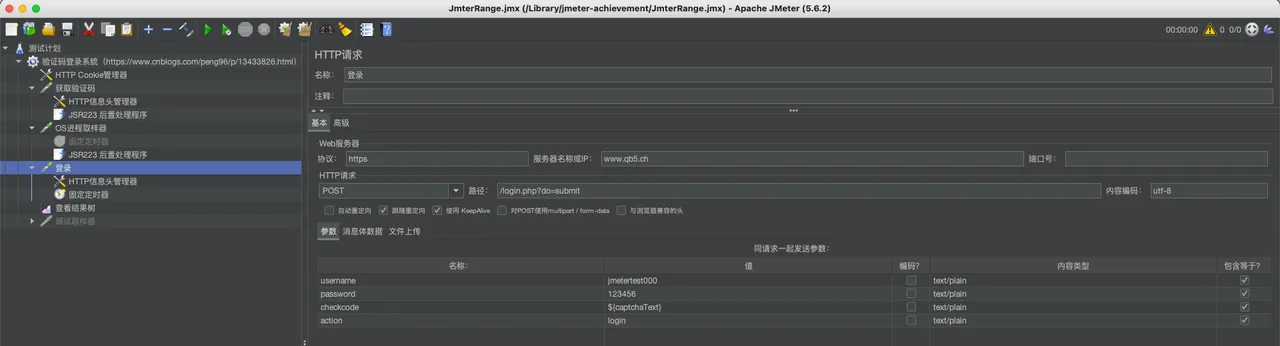
- 添加登录请求:
- 在 Thread Group 下,添加另一个 HTTP Request 采样器,配置为登录请求。
- 在登录请求的参数中,使用 ${captchaText} 引用解析到的验证码文本。
本文作者:精卫
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录