目录
Dify 代码节点调试复盘文档
本文档记录了在 Dify 工作流中配置代码节点(Python)从零到可用的完整历程,包含遇到的问题、原因分析及解决方案,以供后期复盘查看。
一、背景
在工作流中,需要将 HTTP 节点返回的考勤 JSON 数据,经过清洗、统计后,生成一份简洁的考勤报告。最初使用 LLM 节点直接处理原始 JSON,存在以下问题:
- 处理速度慢(内部模型耗时 ~30s)
- Token 消耗大(8.6K tokens)
- 输出不稳定,内容冗长
为解决上述问题,引入代码节点进行数据预处理,再将结果传给 LLM 节点生成报告。最终方案进一步优化:代码节点直接生成报告文本,完全去掉 LLM 节点。
二、工作流结构
textHTTP节点 → 代码节点 → 结束/输出节点
| 节点 | 功能 |
|---|---|
| 考勤查询HTTP | 调用 API 获取考勤 JSON 数据 |
| 代码执行 | 解析 JSON → 统计状态 → 生成报告文本 |
| 结束/输出 | 返回最终报告 |
三、遇到的问题及解决方案
问题1:AttributeError: 'str' object has no attribute 'get'
报错信息:
textAttributeError: 'str' object has no attribute 'get' error: exit status 255
原因分析: HTTP 节点返回的 body 是 JSON 字符串,而非已解析的字典对象。代码中直接调用了 .get() 方法,但字符串没有该方法。
解决方案: 在代码开头添加类型判断,对字符串类型进行 json.loads() 解析:
pythonif isinstance(http_response, str):
try:
http_response = json.loads(http_response)
except json.JSONDecodeError:
return {"result": "错误:JSON解析失败"}
问题2:Output result is missing
报错信息:
textOutput result is missing
原因分析: Dify 代码节点的输出变量配置有严格要求:
- 输出变量名必须与 return 返回字典的外层 key 一致
错误写法:
python# 错误:直接返回数据,没有外层 key
return {"stats": stats}
正确写法:
python# 正确:外层 key 必须与输出变量名一致
return {"result": {"stats": stats}}
四、最终可用代码与节点配置
4.1 最终可用代码
pythonimport json
from collections import Counter
def main(http_response):
# ===== 输入处理:字符串 → 字典 =====
if isinstance(http_response, str):
try:
http_response = json.loads(http_response)
except json.JSONDecodeError:
return {
"result": "❌ 错误:JSON解析失败,请检查数据格式"
}
if not isinstance(http_response, dict):
return {
"result": f"❌ 错误:输入类型错误,期望dict,实际为{type(http_response)}"
}
# ===== 数据提取 =====
if http_response.get("code") != 1:
return {
"result": "❌ 错误:接口返回异常"
}
records = http_response.get("data", [])
if not records:
return {
"result": "📊 本月无考勤数据"
}
# ===== 状态映射 =====
status_map = {
0: "未排班",
1: "休息",
2: "正常上班",
3: "旷工",
4: "缺卡",
5: "请假",
6: "早退",
7: "迟到",
8: "出差",
9: "外出",
10: "加班"
}
abnormal_codes = {3, 4, 6, 7}
# ===== 统计 =====
stats = {name: 0 for name in status_map.values()}
abnormal_dates = []
for record in records:
att_date = record.get("att_date", "未知日期")
status_code = record.get("status")
status_name = status_map.get(status_code, f"未知({status_code})")
stats[status_name] = stats.get(status_name, 0) + 1
if status_code in abnormal_codes:
abnormal_dates.append(att_date)
# ===== 计算关键指标 =====
total_days = len(records)
work_days = stats.get("正常上班", 0)
rest_days = stats.get("休息", 0)
leave_days = stats.get("请假", 0)
absent_days = stats.get("旷工", 0)
missing_days = stats.get("缺卡", 0)
early_days = stats.get("早退", 0)
late_days = stats.get("迟到", 0)
other_abnormal = len(abnormal_dates) - absent_days - missing_days - early_days - late_days
# ===== 构建报告 =====
report = "📊 **考勤报告**\n\n"
# 表格
report += "| 状态 | 天数 |\n"
report += "|------|------|\n"
status_items = [
("正常上班", work_days),
("休息", rest_days),
("请假", leave_days),
("旷工", absent_days),
("缺卡", missing_days),
("早退", early_days),
("迟到", late_days),
("其他异常", other_abnormal)
]
for name, count in status_items:
if count > 0:
report += f"| {name} | {count}天 |\n"
report += "\n"
# 异常信息
if abnormal_dates:
formatted_dates = [d[5:] for d in abnormal_dates] # "2026-06-01" -> "06-01"
dates_str = "、".join(formatted_dates)
report += f"⚠️ **异常记录**(共{len(abnormal_dates)}天):{dates_str}\n\n"
if absent_days > 0:
report += "💡 **建议**:本月旷工较多,建议加强考勤管理。"
elif missing_days > 0:
report += "💡 **建议**:存在缺卡情况,请提醒员工及时打卡。"
elif early_days > 0 or late_days > 0:
report += "💡 **建议**:存在迟到/早退情况,请关注员工出勤纪律。"
else:
report += "💡 **建议**:存在异常考勤,请关注具体情况。"
else:
report += "✅ 本月考勤正常,无异常记录。"
return {
"result": report
}
4.2 页面配置如下
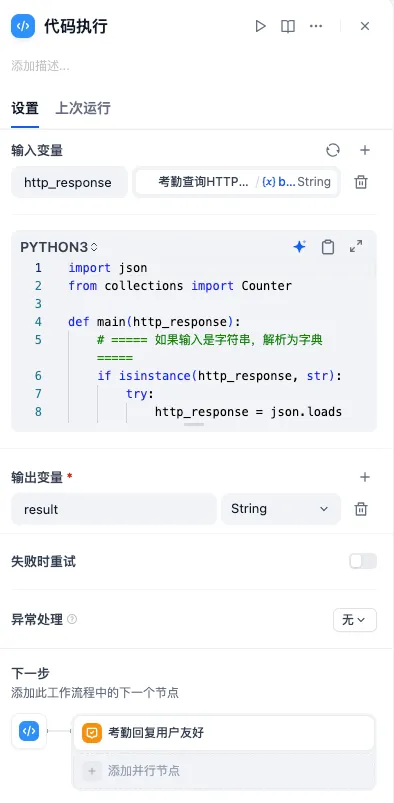
五、优化效果对比与总结
优化效果对比
| 指标 | 优化前(LLM处理原始JSON) | 优化后(代码节点生成报告) |
|---|---|---|
| 工作流节点 | 3个(HTTP → 代码 → LLM) | 2个(HTTP → 代码) |
| 总耗时 | ~30秒 | <1秒 |
| Token消耗 | 8.6K | 0 |
| 输出稳定性 | 依赖LLM,不稳定,接口返回相同的内容 经LLM处理后结果不一致 | 完全可控,稳定 |
| 成本 | 消耗Token | 几乎为0 |
总结
- Dify 代码节点的输出必须包一层外层 key,且与输出变量名一致
- HTTP 节点返回的 body 是字符串,需要手动 json.loads() 解析
- 避免在变量引用中使用中文键名,Dify 解析器对此支持不完善
- 能用代码节点计算的就别用 LLM,效率提升显著
参考文档:
本文作者:精卫
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录